Hoe wij een AI-model trainden voor veilige zorgchatbots Michiels zoektocht door AI – met Aritra
28 april 2026 – Leestijd: 10 minuten – Geschreven door: Aritra Biswas


We bouwden een lokale classifier die GPT-4.1-mini evenaart op accuratesse (98%) en 720 keer sneller is. Dit is hoe we dat deden en wat ons daarbij verraste aan GPT.
Het probleem De veiligheidscheck bepaalt of de chatbot mag antwoorden
Stel je voor: je typt een vraag in een zorg-chatbot. Soms is dat iets praktisch zoals “kan ik mijn afspraak verzetten?” Soms iets zoals “ik wil niet meer leven.”
Elke vraag die binnenkomt gaat eerst langs een veiligheidscheck. Daarin bepaalt het systeem of de chatbot zelf mag antwoorden of dat er een zorgverlener aan te pas moet komen. Zo’n check is in de zorg een klinische eis. 1
In de zorg-chatbot waar wij dit onderzoek op uitvoerden, toetst het systeem elke inkomende vraag op vier dimensies:
- Gaat de vraag over de chatbot zelf? (“Wat ben jij?”, “Hoe werk je?”)
- Is er sprake van een medisch spoedgeval? (“Mijn kind stikt”, “pijn op de borst”)
- Gaat het om algemene zorginformatie of om een persoonlijke medische vraag? Dat laatste hoort bij een zorgverlener.
- Welk type vraag is het? Afspraak, informatie, personeel, noodgeval, elk type gaat naar een andere afhandelaar.
Er kunnen twee soorten fouten optreden. Als een spoedgeval door de filter glipt, heb je een patientveiligheidsincident. Als de filter te streng is, worden gewone vragen ten onrechte geblokkeerd. Beide gebeuren in de praktijk en beide zijn ongewenst. 1
De oorspronkelijke opzet Vier API-calls per vraag
In de productieversie werden deze vier checks uitgevoerd met vier losse aanroepen naar externe diensten: 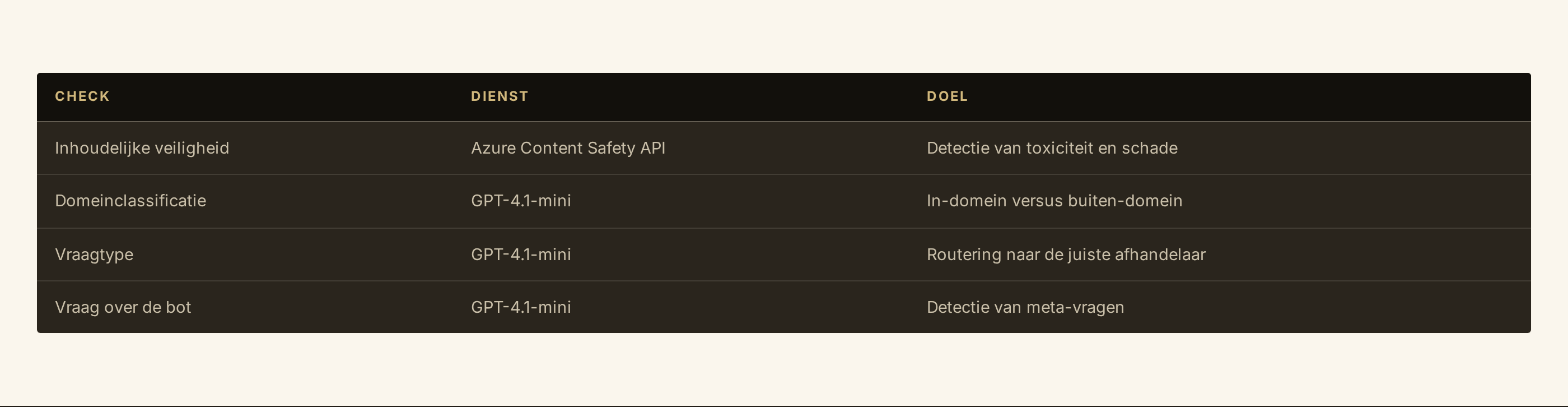
In januari en februari 2026 leverde dat 1.285 API-calls op voor 130 unieke patientenvragen. Elke aanroep kost milliseconden en een paar cent. In een flink deel van de gevallen kwam er ook geen bruikbaar antwoord terug, daarover hieronder meer.
Kunnen we deze hele pijplijn vervangen door een lokale classifier die even nauwkeurig is als GPT, maar zonder de operationele risico’s?
Een onverwachte ontdekking GPT levert in 32% van de gevallen geen geldig antwoord
Voor we begonnen met bouwen, analyseerden we eerst de bestaande pijplijn. De domeinclassificatie van GPT-4.1-mini had een parsingfoutpercentage van 32%. Van de 341 aanroepen gaven er ongeveer 110 een antwoord terug dat niet als geldige JSON te lezen was. En dat ondanks een prompt met voorbeelden, expliciete formaatinstructies en duidelijke beperkingen op de output.
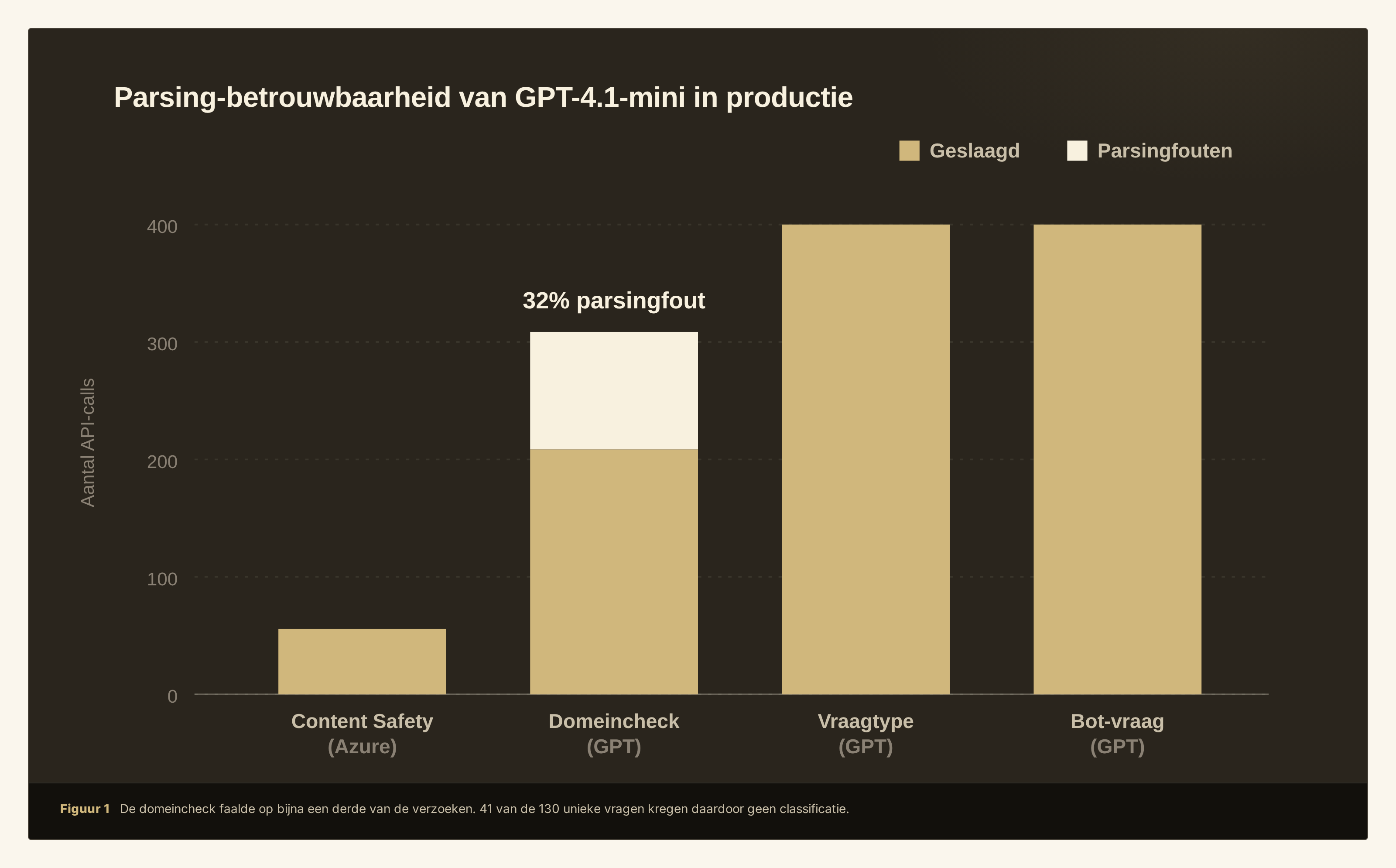
Dit patroon komt vaker voor. Onderzoek naar gestructureerde output van taalmodellen laat zien dat zelfs met zorgvuldige prompt-engineering de naleving van het uitvoerformaat per taak en per modelversie flink kan verschillen. 2 Voor een veiligheidscheck is dat te veel. Een classifier die op een derde van de vragen niets bruikbaars teruggeeft, kun je niet gebruiken, ook niet als de rest wel goed gaat.
Die 41 vragen worden in de praktijk geblokkeerd of ongefilterd doorgelaten. Het eerste is slechter voor de bezoeker, het tweede is een risico.
Het ontwerp Twee lagen
In plaats van GPT verder te tunen met prompt-engineering of retry-logica, bouwden we zelf een pijplijn in twee lagen: een deterministische regel-laag voor het voorspelbare verkeer, en een klein ML-model voor de rest.
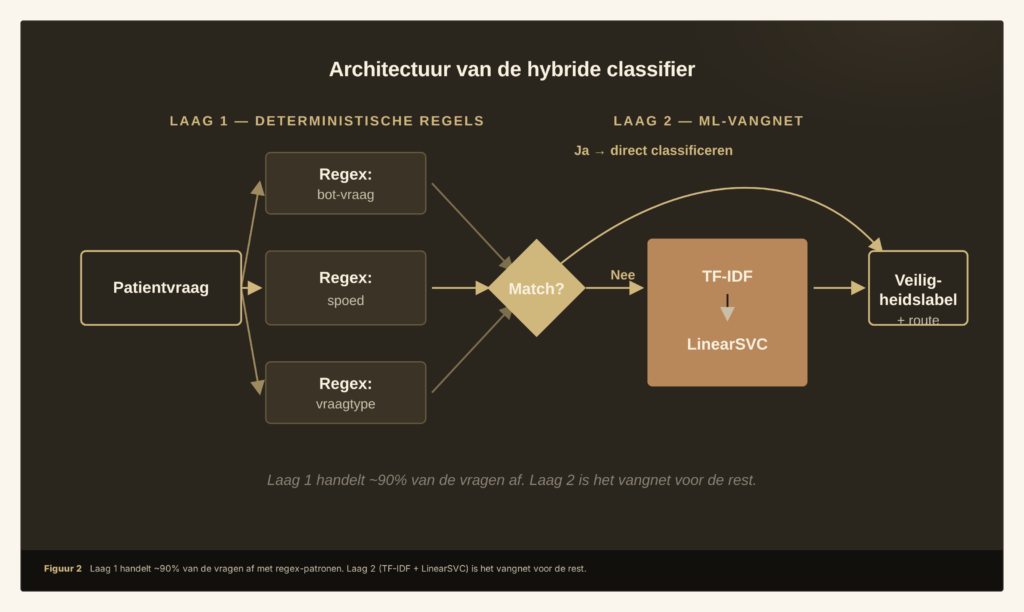
Laag 1: regex-patronen
De eerste laag bestaat uit handgeschreven patronen (regex) voor de meest voorkomende vormen:
- Vragen over de bot: “wie ben je”, “wat kan je doen”, “hoe werk je”
- Spoedgevallen: “stikt”, “suïcide”, “pijn op borst”, “hartaanval”, “bewusteloos”
- Domeinfilter: herkent vragen waarin een bezoeker om een persoonlijk medisch oordeel vraagt (“ik heb [symptoom], wat moet ik doen?”)
- Vraagtype-routering: INFORMATIE, AFSPRAAK, SPOED, PERSONEEL, enzovoorts
Deze laag handelt ruim 90% van de productievragen af, vrijwel zonder rekentijd. En hij werkt deterministisch: dezelfde vraag geeft altijd dezelfde classificatie. Dat helpt als je later moet kunnen uitleggen waarom een vraag wel of niet is doorgelaten. 3
Laag 2: machine-learning als vangnet
Sommige vragen herkent de regel-laag niet met zekerheid: dubbelzinnige formuleringen, nieuwe varianten, of content die buiten het domein valt. Daarvoor hebben we een klein ML-model.
Kenmerkextractie. We gebruiken een dubbele TF-IDF-aanpak. TF-IDF staat voor term frequency–inverse document frequency en kijkt welke woorden typisch zijn voor welke categorie. We laten hem op twee niveaus tegelijk werken: woord-n-grammen (1 tot 3 woorden) voor de betekenis, en karakter-n-grammen (3 tot 5 tekens) voor robuustheid bij typefouten en spellingsvariaties. Die komen veel voor in patiententekst. 4
Model. Een LinearSVC met CalibratedClassifierCV: een lichte classifier met een kalibratielaag erbovenop, zodat de kans-uitvoer ook werkelijk als kans te lezen is. Met balanced class weights corrigeren we de scheve verdeling tussen categorieën. Onveilige vragen zijn zeldzaam, maar je wilt ze wel allemaal vangen.
Trainingsdata. 1.044 synthetische voorbeelden, verdeeld over 19 categorieën. De voorbeelden dekken formeel Nederlands, spreektaal, Engels, veelvoorkomende typefouten, dialect en chattaal. We gebruikten geen productiedata voor de training.
Harde overrides. Voor kritieke categorieën zoals suïcide, jailbreak-pogingen en instructies voor gevaarlijk gedrag, staan er aparte patronen die altijd aanslaan, ongeacht de uitkomst van het ML-model.
De taxonomie: negentien categorieën
De classifier wijst aan elke vraag een specifieke categorie toe. De taxonomie dekt vijf domeinen:

GPT-4.1-mini gaf binaire labels (relevant/niet-relevant, spoed/geen-spoed). De hybride classifier geeft een specifieke categorie. Daarmee kan de chatbot verderop in de pijplijn een gerichter vervolg kiezen.
Resultaten
We vergeleken de hybride classifier met alle 130 productievragen. Als grondwaarheid gebruikten we de meerderheidsstem van GPT-4.1-mini over meerdere aanroepen.
Accuratesse: 98% tot 100% over alle dimensies
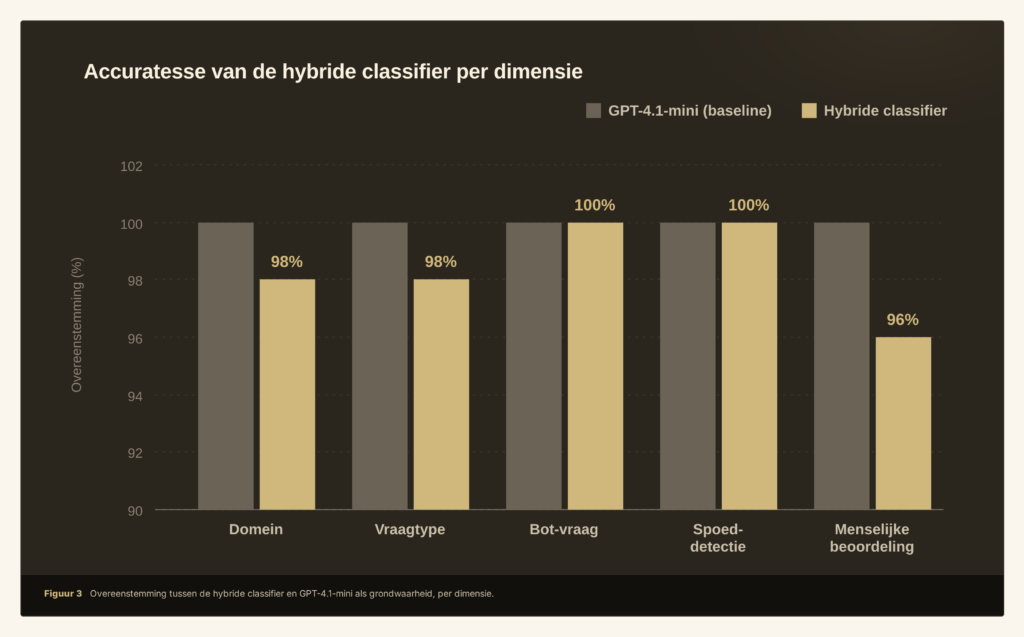

De twee “afwijkingen” in de domeincheck waren bloed prikken en vallen, losse woorden die GPT als buiten-domein aanmerkte, terwijl ze in een zorgcontext prima als informatievraag kunnen tellen. De drie afwijkingen in vraagtype waren randgevallen waarin de hybride classifier terugvalt op INFORMATIE en GPT op OVERIG. In beide gevallen gaat het om een interpretatieverschil, geen classificatiefout.
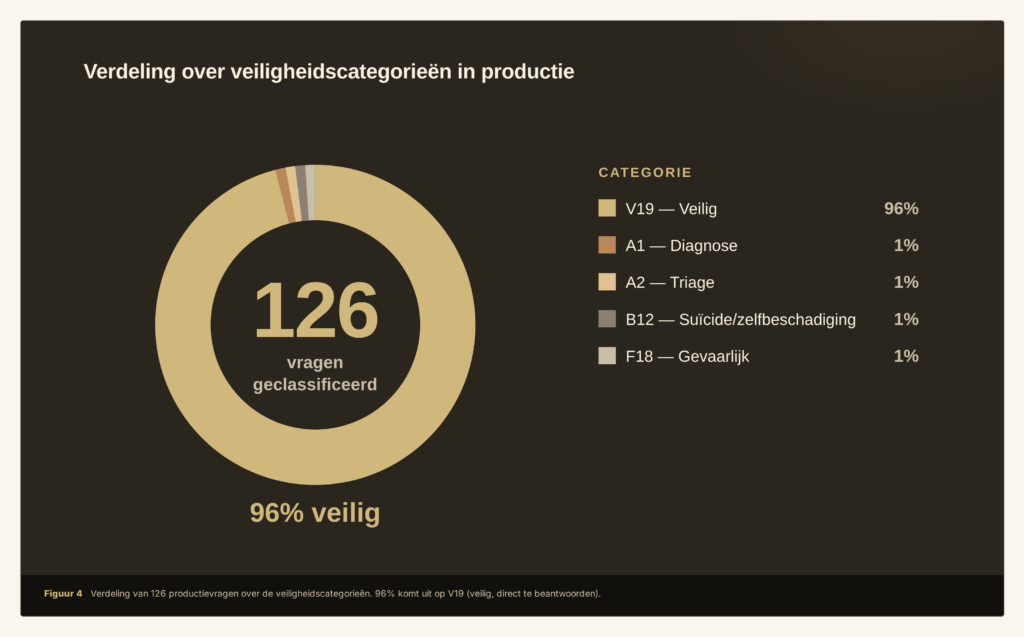
Verdeling van de veiligheidscategorieën
De 4% die als onveilig werd gemarkeerd, viel in de categorieën waar menselijk oordeel nodig is: medische diagnose (A1), triage (A2), suïcide en zelfbeschadiging (B12) en gevaarlijke content (F18). Op die set waren de classificaties correct.
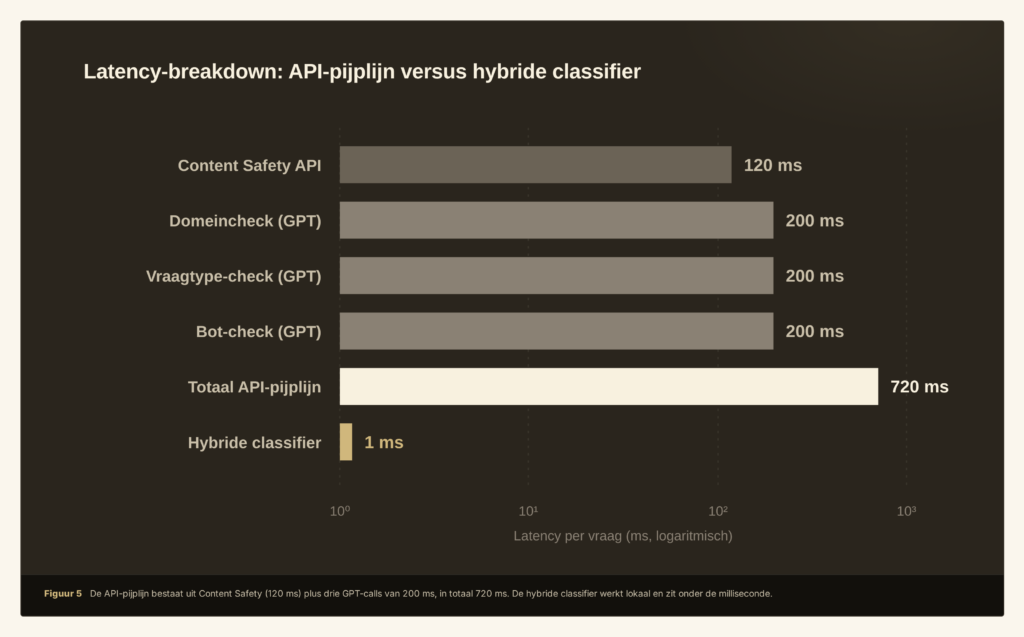
Snelheid: van 720 milliseconden naar 1
Voor de gebruiker is de veiligheidscheck daarmee onmerkbaar. Voor vragen die de regex-laag afhandelt, zit de totale rekentijd onder de milliseconde. Onderzoek naar chatbots laat zien dat reactietijden boven de 200 ms voor gebruikers al merkbaar zijn. 5

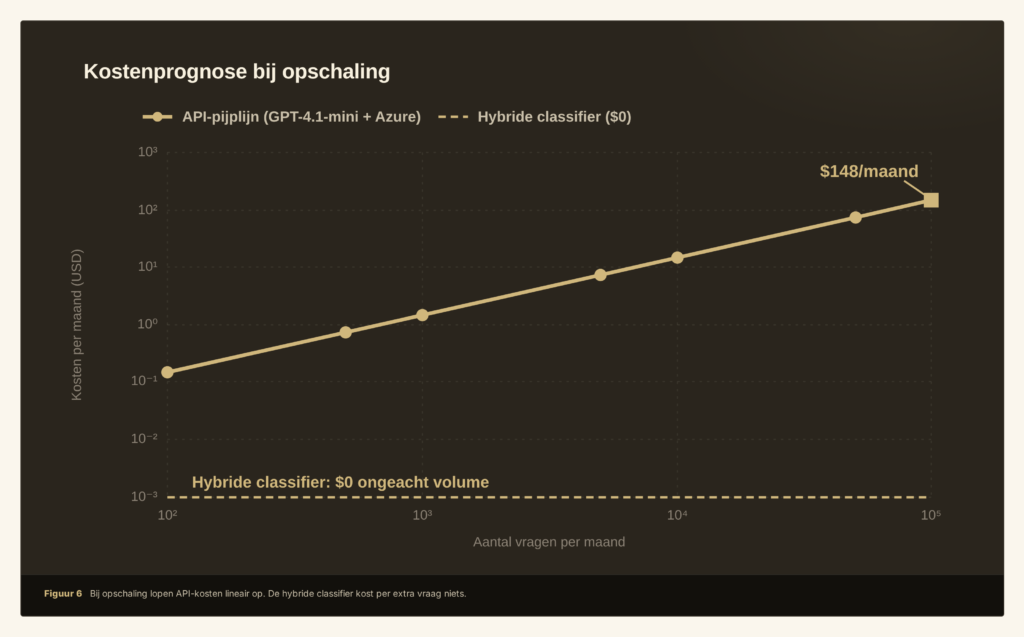
Kosten: lineair versus nul
Bij het huidige volume is het verschil in euro’s verwaarloosbaar. Zorg-chatbots worden echter meestal ingezet om callcenters te ontlasten en zelfservice te verbeteren. 6 Bij opschaling lopen alleen al de veiligheidschecks in de honderden dollars per maand. De hybride classifier draait als Python-pakket met twee afhankelijkheden (numpy, scikit-learn) op dezelfde server als de chatbot zelf, en kost per extra vraag niets.

Beschouwing
Onbetrouwbare output van LLM’s wordt onderschat
Een parsingfout van 32% op een overzichtelijke classificatietaak is hoger dan je zou verwachten. De prompt vroeg GPT-4.1-mini om {"relevant": true/false, "confidence": 0.9, "explanation": "..."} terug te geven. Dat is geen ingewikkelde opdracht, maar toch gaf ongeveer één op de drie aanroepen iets onlezbaars terug.
Dit is niet iets dat alleen bij ons speelt. Onderzoek naar gestructureerde output bij taalmodellen laat vergelijkbare percentages zien, vooral als een model tegelijk moet redeneren over inhoud en zich moet houden aan formaatregels. 2 In productie blijven zulke fouten vaak onzichtbaar in dashboards, terwijl individuele gebruikers er wel last van hebben.
Het meeste veiligheidswerk is patroonherkenning
De meeste vragen aan een zorg-chatbot vallen in voorspelbare patronen. “Waar kan ik parkeren?” is duidelijk veilig. “Ik wil suïcide plegen” is duidelijk een noodgeval. Voor zulke signalen heb je geen redenerend taalmodel nodig. Patroonherkenning doet het werk sneller en altijd op dezelfde manier.
Dit sluit aan bij eerder onderzoek naar efficiënte tekstclassificatie. Joulin e.a. lieten zien dat eenvoudige classifiers deep-learning-modellen kunnen evenaren bij welomlijnde taken, tegen een fractie van de rekentijd. 7 Hoe duidelijker de categoriegrenzen en hoe voorspelbaarder de input, hoe meer die winst oplevert.
Synthetische trainingsdata werkt, in een afgebakend domein
We trainden het ML-model volledig op synthetische voorbeelden, zonder productiedata in de trainingsset. Dat werkt in dit geval omdat de veiligheidsclassificatie een afgebakend probleem is: de categorieën liggen vast, de taalpatronen zijn voorspelbaar (Nederlands medisch vocabulaire, veelvoorkomende typefouten, chattaal) en de randgevallen zijn op te sommen.
Voor open taken zou deze aanpak niet werken. Binnen een vaste taxonomie kom je echter vrij ver met synthetische data, mits het categorieontwerp doordacht is. 8
Determinisme weegt zwaarder dan flexibiliteit
GPT-4.1-mini is niet-deterministisch: bij dezelfde vraag kunnen verschillende aanroepen verschillende classificaties opleveren. Voor algemene toepassingen is dat geen bezwaar. In een veiligheidscontext wordt het lastiger. Bij een vraag over suïcide wil je dat het label elke keer hetzelfde is, anders kun je er geen beleid op bouwen.
De hybride classifier doet dat wel. Dezelfde input geeft elke keer dezelfde output. Dat past ook bij de EU AI Act, die voor hoogrisico-AI in de zorg expliciet voorspelbaarheid en menselijk toezicht voorschrijft. 3
Beperkingen en afwegingen
Deze aanpak heeft ook grenzen:
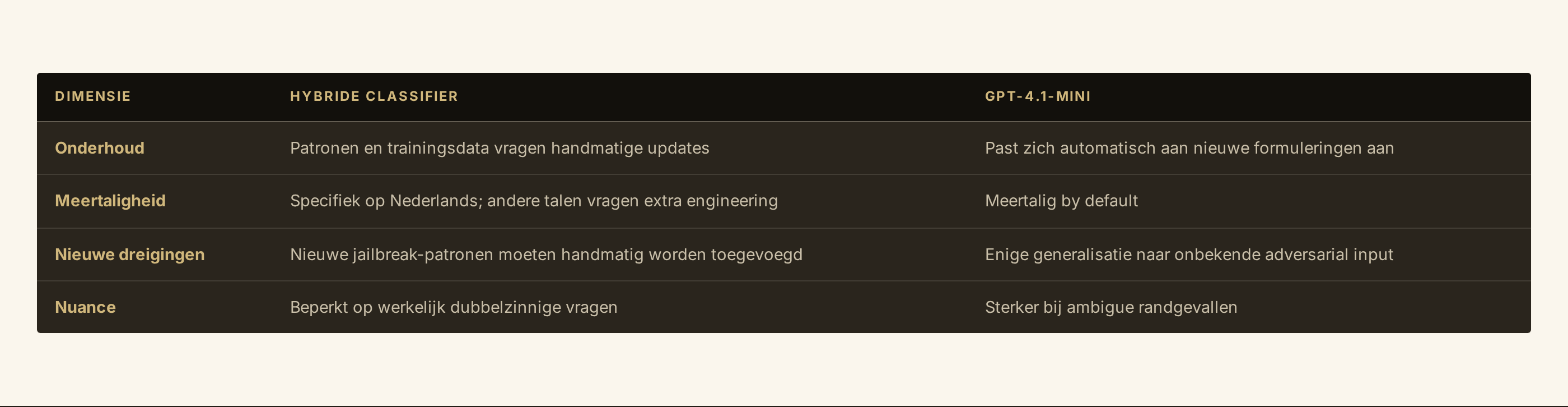
Voor deze chatbot wegen die nadelen licht. 96% van de vragen is veilig, en het taalgebruik is voorspelbaar Nederlands. Bij een meertalig of actief vijandig gebruikspatroon zou een combinatie interessanter worden: de lokale classifier voor de standaardgevallen, een LLM voor het restje.
Voor veiligheidskritische toepassingen in de zorg is een klein, deterministisch model vaak betrouwbaarder dan een groot taalmodel dat in een op de drie gevallen geen bruikbaar antwoord teruggeeft.
Conclusies
- Een lokale regex-plus-ML-pijplijn evenaart GPT-4.1-mini op accuratesse (98%) voor veiligheidsclassificatie in een zorg-chatbot, terwijl parsingfouten, non-determinisme, latency en kosten wegvallen.
- GPT-4.1-mini had in productie een parsingfout van 32% op gestructureerde JSON-output. Dit type onbetrouwbaarheid laat zich moeilijk wegwerken met alleen prompt-engineering.
- De versnelling is 720x (van 720 ms naar 1 ms per vraag). De veiligheidscheck is daardoor onmerkbaar voor de gebruiker.
- Synthetische trainingsdata volstaat voor afgebakende classificatiedomeinen met voorspelbare taalpatronen.
- Determinisme weegt zwaar in veiligheidskritische zorgsystemen. LLM-classifiers kunnen dat niet garanderen.
Aanbevelingen voor de praktijk
Begin niet automatisch bij een LLM. Voor welomlijnde classificatietaken in een veiligheidskritische context is een lokale classifier vaak betrouwbaarder en voorspelbaarder. De ontwikkelkost valt mee, de classifier hierboven past in ongeveer 500 regels Python.
Meet hoe vaak je LLM-calls een leesbaar antwoord teruggeven. Dat is een andere vraag dan of het antwoord klopt, en het percentage ligt vaak lager dan je denkt. In een veiligheidscontext is dat doorslaggevend.
Combineer deterministische regels met een probabilistisch vangnet. Regels vangen de voorspelbare gevallen af, waar je geen variatie wilt. Een klein ML-model dekt de rest zonder dat je de controleerbaarheid verliest.
Ontwerp synthetische trainingsdata bewust. Neem formeel taalgebruik, spreektaal, typefouten en dialect mee. In de zorg betekent dat ook volkstaal naast vakjargon.
Gebruik determinisme als uitgangspunt. In hoogrisicotoepassingen helpt reproduceerbaarheid bij audits en verantwoording. De EU AI Act schrijft dit expliciet voor bij hoogrisico-AI in de zorg. 3
Dit onderzoek is uitgevoerd door Proud Nerds als onderdeel van ons werk rond AI in de zorgcommunicatie. De testset is gebaseerd op echte productiedata uit het zorgdomein, januari–februari 2026. Voor vragen of samenwerking: neem contact op.
Bronnen
- World Health Organization (2021). “Ethics and Governance of Artificial Intelligence for Health.” WHO. who.int/publications/i/item/9789240029200
- Liu, J. et al. (2024). “Is Your LLM Secretly a World Model of the Internet? Model-Based Planning for Web Agents.” arXiv preprint arXiv:2411.19461. Documenteert uitdagingen rond gestructureerde output van LLM’s.
- Europese Commissie (2024). “Verordening (EU) 2024/1689 — Artificial Intelligence Act.” Publicatieblad van de Europese Unie. Artikel 14 vereist menselijk toezicht en voorspelbaarheid voor hoogrisico-AI in de zorg.
- Lui, M. & Baldwin, T. (2011). “Cross-Domain Feature Selection for Language Identification.” Proceedings of IJCNLP. Laat zien dat karakter-n-grammen effectief zijn bij ruis in de input.
- Følstad, A. & Skjuve, M. (2019). “Chatbots for Customer Service: User Experience and Motivation.” Proceedings of the 1st International Conference on Conversational User Interfaces.
- Laranjo, L. et al. (2018). “Conversational Agents in Healthcare: A Systematic Review.” Journal of the American Medical Informatics Association, 25(9), 1248–1258.
- Joulin, A., Grave, E., Bojanowski, P. & Mikolov, T. (2017). “Bag of Tricks for Efficient Text Classification.” Proceedings of EACL. FastText laat zien dat eenvoudige modellen deep learning kunnen evenaren bij welomlijnde classificatietaken.
- Møller, S. et al. (2023). “Is a Prompt and a Few Samples All You Need? Using GPT-4 for Data Augmentation in Low-Resource Classification Tasks.” arXiv preprint arXiv:2304.13861.
Vragen of samenwerking?
Dit onderzoek is uitgevoerd door Proud Nerds als onderdeel van ons werk rond AI in de zorgcommunicatie. De testset is gebaseerd op echte productiedata uit het zorgdomein, januari–februari 2026.
Contact