Hoe wij de zoekresultaten van een ziekenhuiswebsite 33% beter maakten Een experiment met hybride zoekmethodes: wanneer helpen AI-vectoren, en wanneer staan ze juist in de weg?
7 april 2026 – Leestijd: 15 minuten


Het probleem: zoeken op een website is lastiger dan je denkt
Stel je voor dat je op de website van een ziekenhuis zoekt naar “parkeren”. Je verwacht de pagina “Route en parkeren” bovenaan. Simpel, toch? Het woord staat letterlijk in de titel.
Maar wat als je zoekt op “verdoving in je rug”? Dan verwacht je informatie over een ruggenprik, maar dat woord staat nergens in je zoekopdracht. Een traditionele zoekmachine die alleen op woordovereenkomst zoekt, vindt dit niet.
Dit is het fundamentele probleem bij zoeken op websites: gebruikers zoeken in hun eigen woorden, terwijl de content in vaktaal is geschreven. Een patient typt “buisjes in de oren”, de website noemt het “trommelvliesbuisjes”. Een bezoeker zoekt “hartfilmpje”, de arts noemt het een “ECG”.
Wij bouwden een zoeksysteem dat beide werelden combineert. Maar hoe vind je de juiste balans? En is er eigenlijk wel een balans die voor alle zoekopdrachten werkt?
Drie zoekmethodes in één systeem
Ons zoeksysteem combineert drie methodes die tegelijkertijd werken. Elk heeft een eigen kracht en een eigen zwakte.
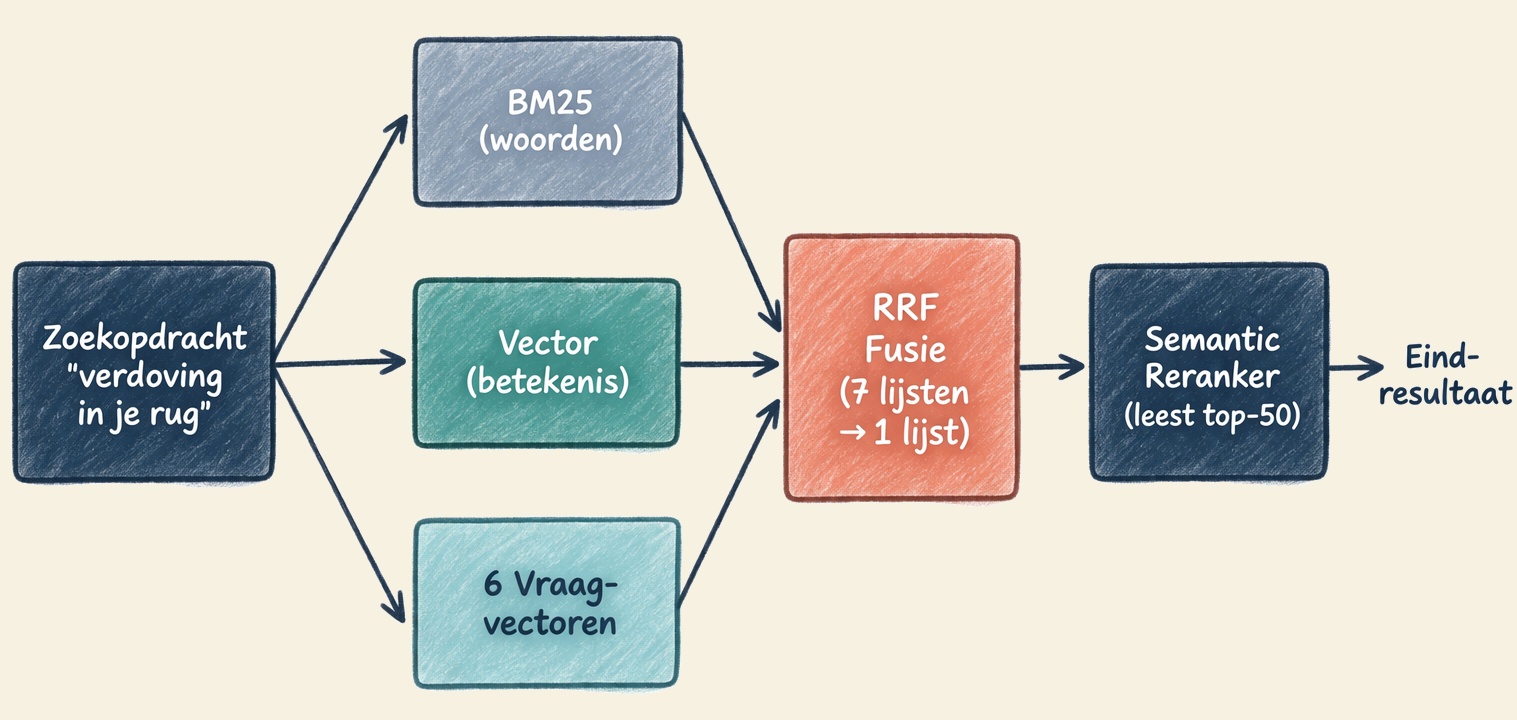
BM25: zoeken op woorden.
De klassieke methode. BM25 zoekt naar exacte woorden in de tekst, titels en trefwoorden van pagina’s. Werkt uitstekend als je zoekt op “parkeren” en de pagina “Route en parkeren” heet. Werkt niet als je zoekt op “verdoving in je rug” terwijl de pagina “Ruggenprik” heet. Dit is al decennia de standaard in zoekmachines en nog steeds verrassend effectief voor exacte matches. [1]
Vectoren: zoeken op betekenis.
Elke pagina wordt omgezet naar een wiskundige representatie, een vector, die de betekenis van de tekst vastlegt. De zoekopdracht wordt ook omgezet naar een vector. Het systeem vergelijkt dan de betekenissen, niet de woorden. “Verdoving in je rug” en “ruggenprik” hebben vergelijkbare vectoren, ook al delen ze geen enkel woord. [2]
Wij gebruiken zes vectoren per pagina: een voor de inhoud en vijf voor automatisch gegenereerde vragen. Die vragen sluiten aan bij hoe een bezoeker zoekt: “Wat is een ruggenprik?”, “Doet een ruggenprik pijn?”, “Hoe lang duurt een ruggenprik?” Door deze vragen als vectoren op te slaan, vindt het systeem de pagina ook als de bezoeker in vraagvorm zoekt.
Semantic reranker: begrijpend lezen.
Na de eerste selectie leest een AI-model de top-50 resultaten daadwerkelijk. Het begrijpt de context en herschikt de resultaten op basis van begrip, niet op basis van woorden of vectoren. Dit is de meest nauwkeurige maar ook de langzaamste methode, en daarom pas geschikt als het aantal kandidaten al is teruggebracht. [3]
De fusie: Reciprocal Rank Fusion (RRF).
Azure AI Search combineert de resultaten van BM25 en de zes vectoren via een algoritme genaamd RRF. Elk zoekpad levert een ranglijst op. RRF combineert deze zeven ranglijsten tot een enkele lijst op basis van rankposities, niet op basis van scores. [4] Daarna herschikt de semantic reranker de top-50.
De onderzoeksvraag
Elke vector heeft een gewicht dat bepaalt hoeveel invloed die heeft in de RRF-fusie. Een hoger gewicht betekent meer invloed op het eindresultaat. De vraag was:
Wat zijn de optimale gewichten voor de vectorcomponenten ten opzichte van BM25?
Te hoge vectorgewichten kunnen ertoe leiden dat exacte woordmatches verdwijnen. Te lage gewichten maken de vectoren nutteloos. Ergens zit een optimum. De literatuur is hier helder over: er bestaat geen universeel optimale gewichtsverdeling. De optimale balans is altijd domein-, corpus- en queryafhankelijk. [5] Maar voor onze specifieke context, een ziekenhuiswebsite met een mix van vaktaal en spreektaal, wilden we dat optimum vinden.
Het experiment
We voerden een systematisch experiment uit in drie rondes, met 150 realistische zoekopdrachten en 13 verschillende gewichtsconfiguraties. In totaal lieten we 1.950 beoordelingen uitvoeren.
De testset: 1500 zoekopdrachten
We stelden een testset samen op basis van echte zoekdata uit Google Analytics van een ziekenhuiswebsite, aangevuld met realistische scenario’s:
| Type zoekopdracht | Aantal | Voorbeeld |
| Enkel woord (uit analytics) | 400 | “parkeren”, “bloedprikken”, “dermatoloog” |
| Twee woorden (uit analytics) | 100 | “online inchecken”, “bloed prikken” |
| Enkel woord (realistisch) | 150 | “hernia”, “dialyse”, “rolstoel” |
| Twee woorden (realistisch) | 250 | “parkeren kosten”, “echo zwangerschap” |
| Korte vraag | 300 | “hoe laat gaat het lab open” |
| Lange vraag | 200 | “ik ben bang voor de operatie en wil weten wat er gebeurt” |
| Typefouten/volkstaal | 100 | “buisjes oren”, “verdoving in je rug” |
De verdeling weerspiegelt het werkelijke zoekgedrag: de meeste zoekopdrachten zijn korte keywords, maar de meest waardevolle, waarin een patiënt een antwoord zoekt, zijn langere vragen.
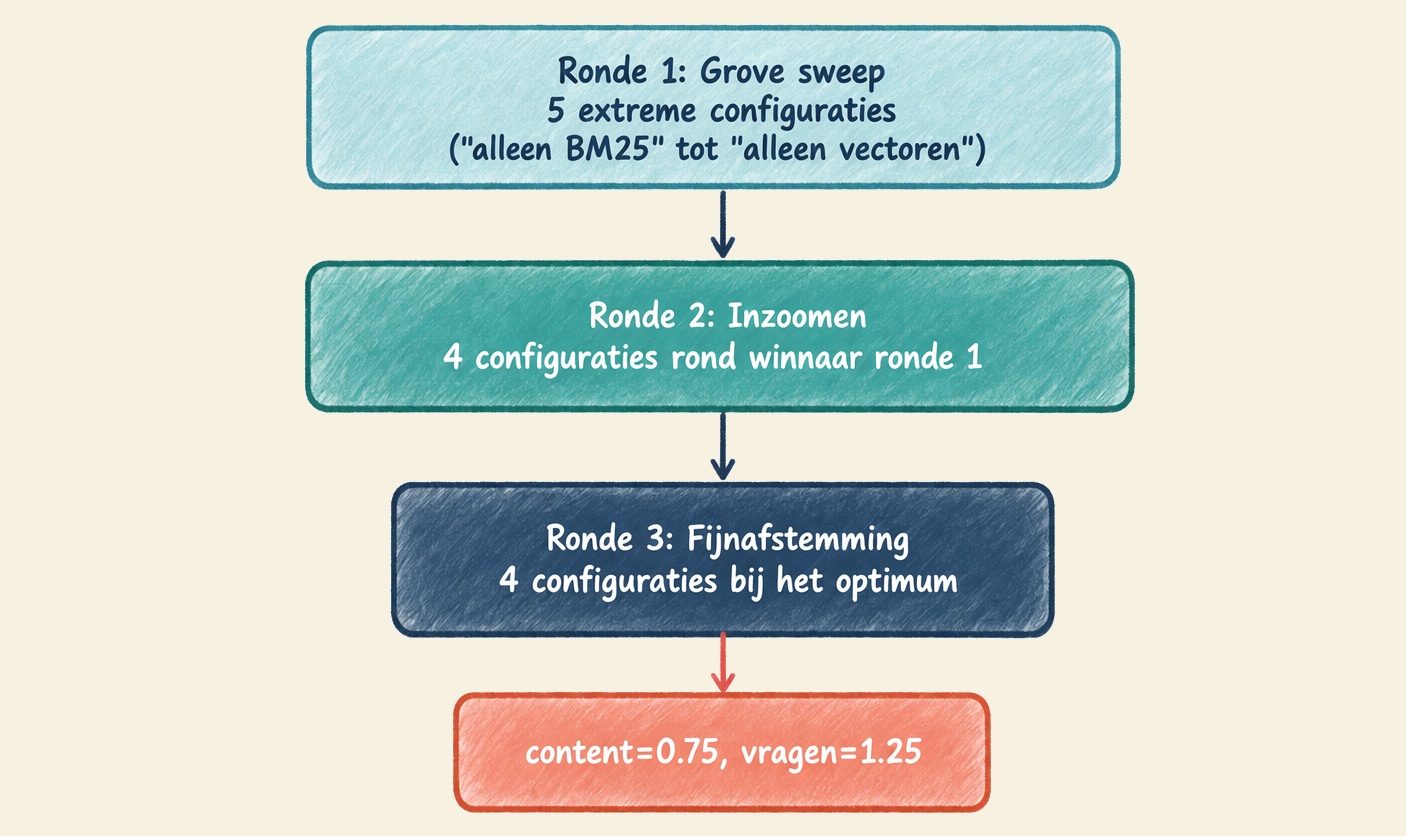
De methode: binary search in drie rondes
We testten niet alle mogelijke combinaties (dat zou duizenden configuraties zijn), maar gebruikten een iteratieve strategie in drie rondes. Elke ronde verfijnde het zoekgebied van de vorige.
De evaluatie:
Per zoekopdracht beoordeelde GPT-4.1-mini de top-5 resultaten op drie criteria:
- Top-1 relevantie (0-3): hoe goed past het eerste resultaat bij de zoekopdracht?
- Top-5 relevantie (0-5): hoeveel van de vijf resultaten zijn daadwerkelijk relevant?
- Keyword match: staat het zoekwoord in de titels van de resultaten?
Het gebruik van een LLM als beoordelaar is een pragmatische keuze. Menselijke evaluatie is nog steeds de gouden standaard [6], maar bij 19.500 beoordelingen is dat niet haalbaar. GPT-4.1-mini biedt een consistente, reproduceerbare beoordeling die goed correleert met menselijk oordeel voor dit type classificatietaak.
Resultaten
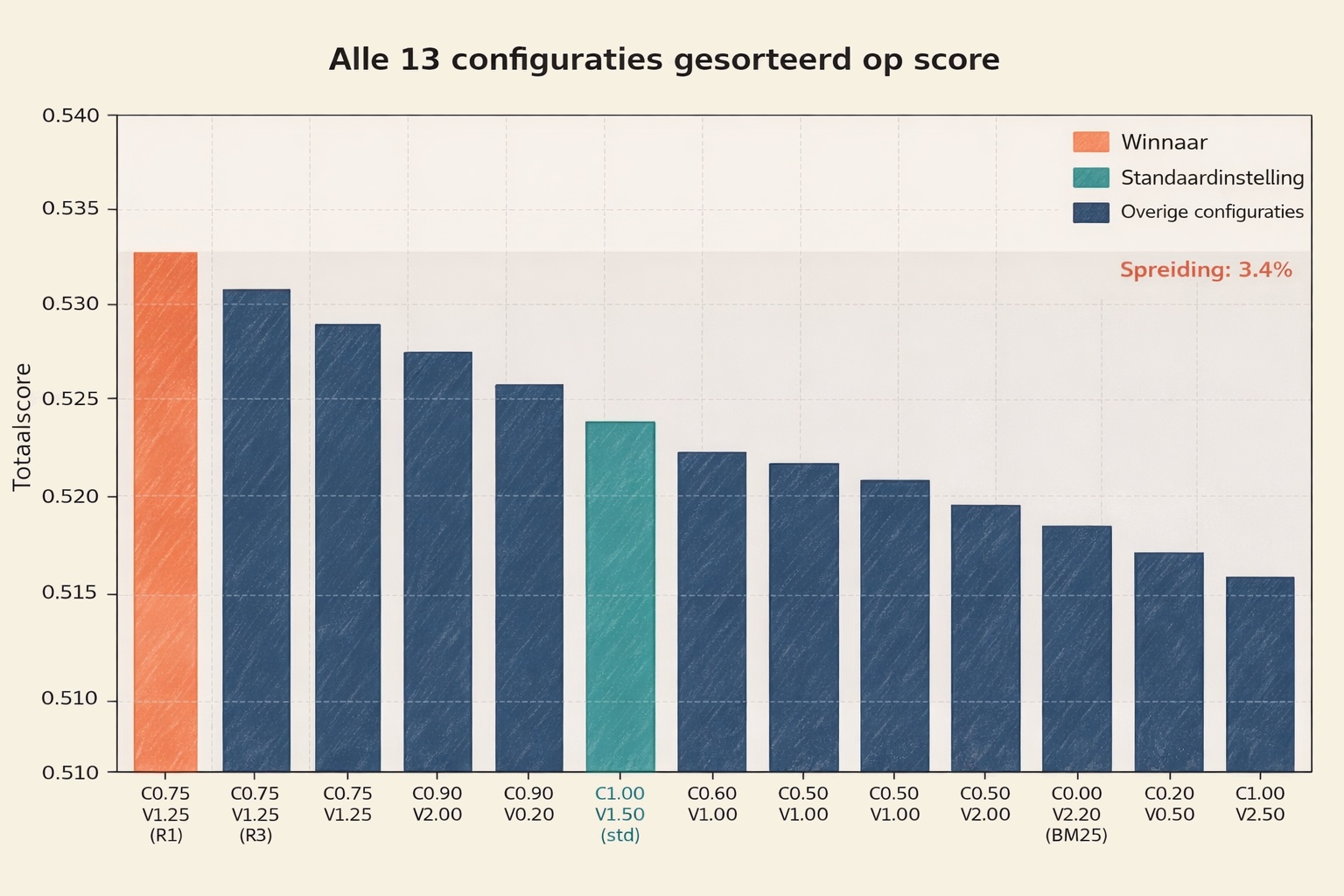
De optimale configuratie:
| Rank | Content gewicht | Vraag gewicht | Totaal vector | Score |
| 1 | 0.75 | 1.25 | 7.00 | 0.533 |
| 2 | 0.75 | 1.25 | 7.00 | 0.531 |
| 3 | 0.50 | 2.00 | 10.50 | 0.529 |
| 4 | 0.90 | 1.50 | 8.40 | 0.526 |
| 5 | 0.30 | 0.20 | 1.30 | 0.525 |
Rank 1 en 2 zijn dezelfde gewichten, getest in twee verschillende rondes. Dat ze nagenoeg dezelfde score opleveren, bevestigt de stabiliteit van het experiment.
De spreiding tussen de beste en slechtste configuratie was slechts 3,5%. Dat is een opvallend klein verschil. De semantic reranker blijkt de dominante factor: ongeacht de vectorgewichten herschikt de reranker de resultaten grotendeels correct. Dit sluit aan bij bevindingen uit de literatuur dat een re-ranker het systeem robuuster maakt tegen suboptimale fusiegewichten. [3] [7]
Het inzicht: vectoren helpen niet overal
De overall score maskeert grote verschillen per type zoekopdracht. En dat is het meest waardevolle inzicht uit dit onderzoek.
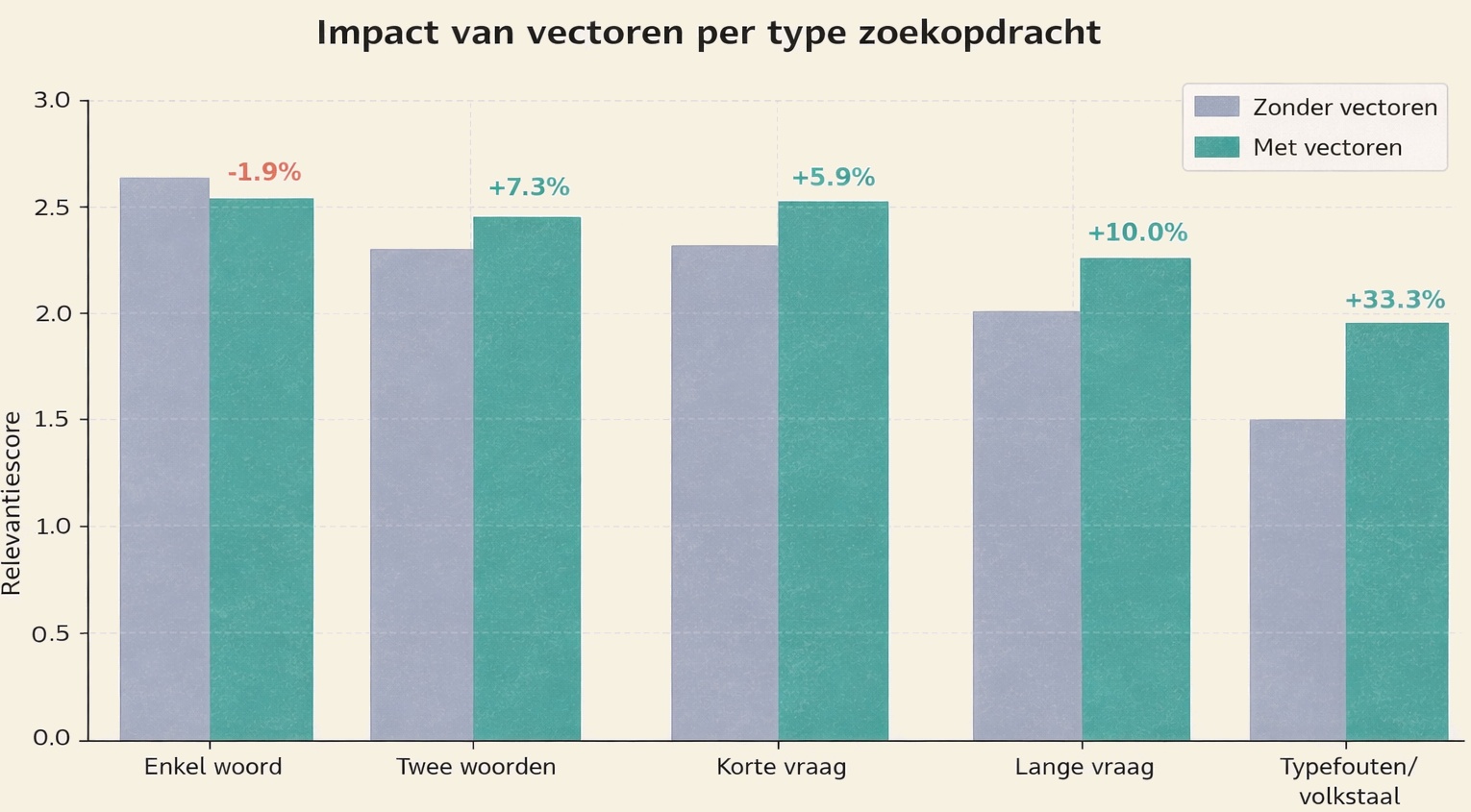
| Type zoekopdracht | Zonder vectoren | Met vectoren | Verbetering |
| Enkel woord (“parkeren”) | 2.58 | 2.52 | -1,9% |
| Twee woorden (“parkeren kosten”) | 2.20 | 2.36 | +7,3% |
| Korte vraag | 2.27 | 2.40 | +5,9% |
| Lange vraag | 2.00 | 2.20 | +10,0% |
| Typefouten/volkstaal | 1.50 | 2.00 | +33,3% |
Vectoren verslechteren de resultaten bij exacte keyword-zoekopdrachten (-1,9%).
Bij het zoeken op “parkeren” vindt BM25 direct de pagina “Route en parkeren”. De vectoren voegen semantisch gerelateerde maar minder relevante pagina’s toe, zoals “Op bezoek” of “Voorzieningen”, die de RRF-fusie verstoren.
Maar vectoren zijn essentieel bij langere zoekopdrachten en typefouten.
“Verdoving in je rug” vindt BM25 niet, er is geen woordoverlap met “Ruggenprik”. De vectoren overbruggen dit verschil: 33% betere resultaten.
Dit patroon is consistent met wat de literatuur laat zien. Op de BEIR-benchmark is het verschil tussen hybride en keyword-only search het grootst bij domeinen met hoog vocabulaire-mismatch (+26-31% nDCG), terwijl bij domeinen waar BM25 al sterk is, de winst kleiner is. [8] De zorg is bij uitstek een domein met hoog vocabulaire-mismatch.
Beschouwing: waarom is het verschil zo klein?
De semantic reranker is de sterkste schakel in de keten. Zelfs als de vectoren suboptimale kandidaten aanleveren, herschikt de reranker ze meestal correct. De vectorgewichten beinvloeden welke 50 pagina’s de reranker te zien krijgt (de recall), maar de reranker bepaalt de uiteindelijke volgorde (de precision).
Dit komt overeen met de architectuur die in de literatuur wordt beschreven: de re-ranker opereert als tweede stage na de fusie en vervangt de fusiegewichten niet, maar verbetert de ranking van de gefuseerde kandidaatlijst. [3] [7] De InfiniFlow-evaluaties (2024) laten zien dat na toevoeging van een re-ranker de nDCG-scores van alle retrieval-combinaties significant verbeteren, ongeacht de onderliggende fusiegewichten. [7]
Dit betekent dat investeren in betere content — duidelijke titels, goede trefwoorden — meer impact heeft dan het eindeloos tunen van vectorgewichten.
De tegenstrijdigheid: BM25 versus vectoren
Er zit een fundamentele spanning in het systeem: hogere vectorgewichten helpen bij vragen, maar schaden bij keywords. De meerderheid van de echte zoekopdrachten (volgens analytics) zijn korte keywords. Maar de meest waardevolle zoekopdrachten, waarin een patient echt een antwoord zoekt, zijn langere vragen.
De optimale balans (content=0.75, vragen=1.25) is een compromis. Maar zou het niet beter zijn om de gewichten dynamisch aan te passen op basis van het type zoekopdracht?
Vervolgonderzoek: zit er een knik?
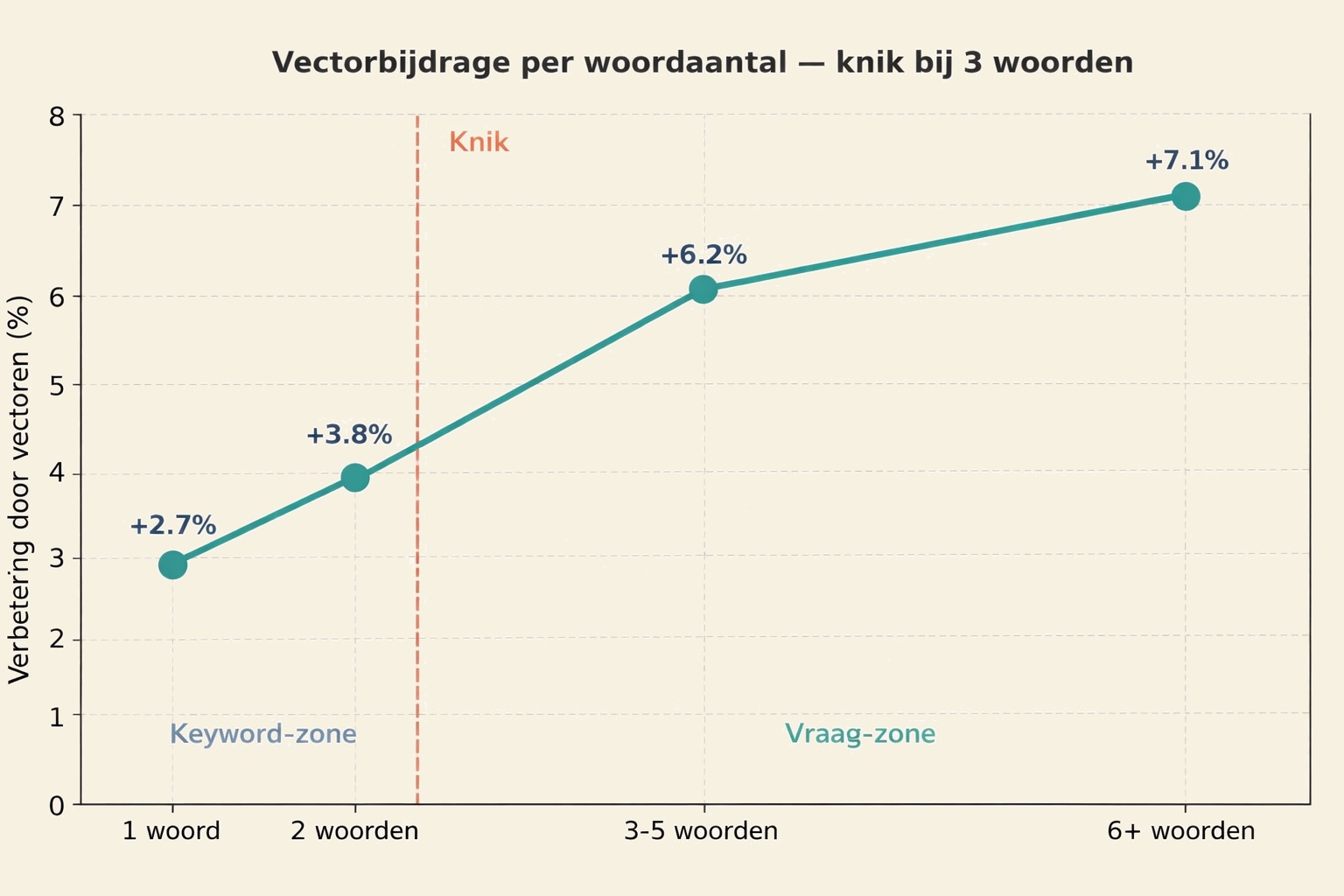
We onderzochten of het verband tussen het aantal woorden in de zoekopdracht en de bijdrage van vectoren horizontaal (geen effect), lineair (evenredige toename) of niet-lineair (met een knik) is.
| Woordaantal | Zonder vectoren | Met vectoren | Verbetering |
| 1 woord | 2.58 | 2.65 | +2,7% |
| 2 woorden | 2.19 | 2.28 | +3,8% |
| 3-5 woorden | 2.13 | 2.27 | +6,2% |
| 6+ woorden | 2.07 | 2.22 | +7,1% |
De Pearson-correlatie tussen het aantal woorden en de vectorbijdrage is r = 0.044 — statistisch nagenoeg nul. Er is geen lineair verband: de vectorbijdrage stijgt niet evenredig met het aantal woorden.
Maar de data laat wel een knik zien bij drie woorden:
| Groep | Gemiddelde vectorbijdrage |
| Keywords (1-2 woorden) | +0.075 |
| Zinnen (3+ woorden) | +0.140 |
Zinnen profiteren bijna twee keer zo veel van vectoren als losse keywords. Het verschil ontstaat niet geleidelijk maar springt bij drie woorden, het punt waarop een zoekopdracht verschuift van een keyword (“parkeren”) naar een vraag (“waar kan ik parkeren”).
De werkelijke voorspeller: type query, niet woordaantal
Bij nadere inspectie bleek het woordaantal een slechte voorspeller. “Parkeren kosten” is twee woorden, maar gedraagt zich als een keyword-zoekopdracht. “Waar kan ik parkeren” is vijf woorden, maar is duidelijk een vraag.
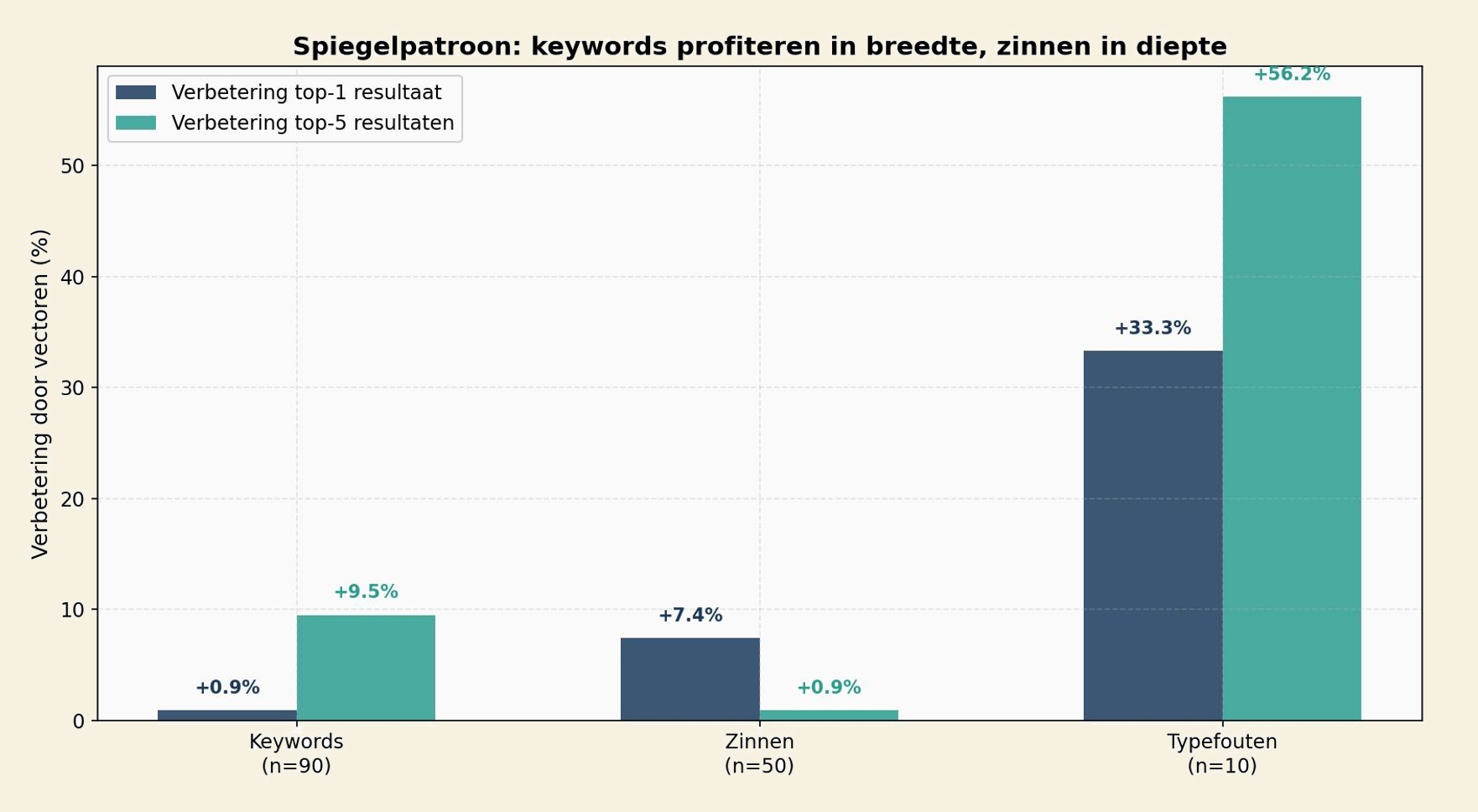
Onze testset bevat een expliciete classificatie per query: keyword (een of meer zoektermen) of zin (een uitgeschreven vraag). Als we de data opnieuw analyseren op basis van dit onderscheid in plaats van woordaantal, wordt het beeld scherper:
| Type | N | Zonder vectoren | Met vectoren | Verbetering top-1 | Verbetering top-5 |
| Keywords | 90 | 2.48 | 2.50 | +0,9% | +9,5% |
| Zinnen | 50 | 2.16 | 2.32 | +7,4% | +0,9% |
| Typefouten | 10 | 1.50 | 2.00 | +33,3% | +56,2% |
Het verschil is nu veel duidelijker. Keywords profiteren nauwelijks van vectoren voor het top-1 resultaat (+0,9%), maar de top-5 wordt 9,5% diverser. Bij zinnen is het omgekeerd: het top-1 resultaat wordt 7,4% relevanter, maar de top-5 verandert nauwelijks.
Dit verklaart ook waarom de eerdere analyse op woordaantal een zwakke correlatie liet zien (r = 0.044). Het woordaantal is een ruisvariabele — “bloedonderzoek nuchter” telt als twee woorden maar is conceptueel een vraag. Het type query is de werkelijke voorspeller.
Hoe verhoudt dit zich tot de literatuur?
Onze bevindingen sluiten aan bij bredere patronen uit de academische literatuur, maar leveren ook een nuance die zelden benoemd wordt.
Het belang van de re-ranker.
Bruch, Gai en Ingber (2023) lieten zien dat een convex combination (gewogen som) beter presteert dan RRF wanneer er gelabelde data beschikbaar is — zelfs met slechts vijftig query-paren. [5] Wij gebruiken RRF omdat Azure AI Search dit standaard aanbiedt en het robuust werkt zonder gelabelde data. Maar het verschil tussen fusie-methodes wordt kleiner naarmate de re-ranker sterker is. Dat bevestigt ook ons resultaat: de re-ranker is de dominante factor, niet de fusie.
Domeinafhankelijkheid van gewichten.
De literatuur is consistent: optimale gewichten zijn domeinafhankelijk. [5] [8] Voor technisch/medisch/juridisch taalgebruik wordt een hogere BM25-weging aanbevolen (0.60-0.70 BM25 versus 0.30-0.40 dense), omdat exacte terminologie cruciaal is. [5] Ons resultaat (content=0.75, vragen=1.25, wat neerkomt op ~60% BM25 in de effectieve balans) valt binnen dit patroon.
Dynamische gewichten.
Hsu en Tzeng (2025) toonden met hun DAT-framework aan dat het dynamisch aanpassen van gewichten per query 2-7,5 procentpunt verbetering oplevert op “hybrid-gevoelige” queries. [9] Onze data onderschrijft dit: keywords en zinnen hebben tegengestelde behoeften. Een classifier die het querytype in real-time detecteert, zou de gewichten per zoekopdracht kunnen optimaliseren.
Risico van te veel retrieval-paden.
Wang et al. (2025) waarschuwen dat hybride accuratesse niet monotoon verbetert met meer retrieval-paden. De prestatie wordt disproportioneel beperkt door de zwakste component — een slecht presterend pad kan de kandidaatpool vervuilen. [10] Dit sluit aan bij onze observatie dat vectoren bij keyword-zoekopdrachten de resultaten licht verslechteren: de vectoren voegen ruis toe die de RRF-fusie verstoort.
BGE-M3: drie representaties in een model.
Chen et al. (2024) presenteerden BGE-M3, een model dat dense, sparse en multi-vector embeddings in een forward pass produceert. [11] De gewichten tussen deze drie representaties worden per downstream-scenario getuned via self-knowledge distillation. Dit is een elegante aanpak die de noodzaak van handmatige gewichtstuning verkleint, maar nog niet beschikbaar is als drop-in vervanging in Azure AI Search.
Conclusies
- De optimale vectorgewichten zijn content=0.75, vragen=1.25.
Dit is een verlaging ten opzichte van de standaardinstellingen van Azure AI Search. De vraag-vectoren wegen zwaarder dan de content-vector, wat logisch is: bezoekers zoeken in vraagvorm, niet in pagina-titelvorm. - Vectoren zijn essentieel voor typefouten en langere vragen
Dit zorgt voor een 10% tot 33% verbetering, maar verstoren exacte keyword-zoekopdrachten licht (-1,9%). Dit is geen bug maar een inherente spanning in hybride search. - De semantic reranker is de dominante factor.
Vectorgewichten hebben slechts 3,5% invloed op het eindresultaat. Dit is goed nieuws: het betekent dat een goede re-ranker het systeem robuust maakt, ook als de vectorgewichten niet perfect zijn. - Het type zoekopdracht is de werkelijke voorspeller, niet het woordaantal.
Keywords en zinnen profiteren op fundamenteel verschillende manieren van vectoren. Dynamische gewichten op basis van querytype is de volgende stap. - Geautomatiseerd testen is essentieel.
Met 1500 zoekopdrachten en 13 configuraties konden we in twee uur een onderbouwde keuze maken. Zonder experiment had intuïtie ons op de verkeerde instelling gezet.
| Instelling | Aanbevolen waarde | Standaardwaarde | Reden |
| Content vector gewicht | 0.75 | 1.0 | Geeft BM25 meer ruimte bij keyword-zoekopdrachten |
| Vraag-vectoren gewicht | 1.25 | 1.5 | Verlaagt de dominantie van vectoren in de RRF-fusie |
Aanbevelingen voor de praktijk
Pas de vectorgewichten aan.
De standaardinstellingen van Azure AI Search zijn niet optimaal voor domeinen met specifiek taalgebruik. Gebruik onze waarden als vertrekpunt en test op je eigen zoekdata.
Investeer in content, niet alleen in techniek.
De re-ranker domineert het eindresultaat. De grootste verbetering komt van duidelijke paginatitels, relevante trefwoorden en synthetische vragen die aansluiten bij hoe gebruikers zoeken.
Herhaal het experiment per domein.
De optimale gewichten zijn domeinafhankelijk. Een kennisbank voor professionals (waar gebruikers de juiste vaktermen kennen) profiteert minder van vectoren dan een patientenwebsite (waar gebruikers in volkstaal zoeken). [5]
Overweeg querytype-detectie.
De grootste vervolgwinst zit niet in betere gewichten, maar in het herkennen van het type zoekopdracht. Een classifier die keywords van zinnen onderscheidt, zou per query de optimale balans kunnen selecteren. [9]
Dit onderzoek is uitgevoerd door Proud Nerds als onderdeel van de ontwikkeling van Proud AI Search, ons AI-gestuurde zoekplatform. De testset is gebaseerd op echte zoekdata van Ziekenhuis Rivierenland.

“Patiënten zoeken in hun eigen woorden, websites antwoorden in vaktaal en dát is precies het gat dat AI-vectoren dicht.”

AI versterking
Wil je meer weten over hoe AI jouw organisatie kan versterken?
Plan vrijblijvend een kennismaking met Michiel Geurts, Business Consultant – AI Innovatie.
Contact
Veelgestelde vragen over het optimaliseren van een RAG Search pipeline
- Wat is hybrid search in een RAG-pipeline?
Hybrid search combineert klassieke woordovereenkomst (BM25) met AI-vectorzoeken. BM25 vindt exacte woordmatches, vectoren begrijpen de betekenis. Door beide te combineren via een fusie-algoritme zoals Reciprocal Rank Fusion (RRF) vangt een RAG-pipeline zowel letterlijke als conceptuele overeenkomsten op. - Wat zijn de optimale gewichten voor vectoren ten opzichte van BM25 in Azure AI Search?
Uit onderzoek met 150 zoekopdrachten en 13 configuraties blijkt dat een content-vectorgewicht van 0.75 en vraag-vectorgewicht van 1.25 de beste balans biedt. Dit is lager dan de standaardinstellingen van Azure AI Search, omdat te hoge vectorgewichten exacte keyword-matches verstoren. - Hoeveel verbeteren vectoren de zoekresultaten in een RAG-pipeline?
Dat hangt af van het type zoekopdracht. Bij exacte keywords verslechteren vectoren de resultaten licht (-1,9%). Bij langere vragen verbeteren ze 5-10%, en bij typefouten of volkstaal zelfs 33%. - Wat doet een semantic reranker in een RAG-pipeline?
Een semantic reranker leest de eerste zoekresultaten opnieuw en beoordeelt ze op inhoudelijke relevantie. Onderzoek toont aan dat de reranker de dominante factor is: vectorgewichten beïnvloeden het eindresultaat slechts 3,5%. - Wat is Reciprocal Rank Fusion (RRF) en hoe werkt het?
RRF is een algoritme dat meerdere ranglijsten combineert tot één eindrangschikking. Elk zoekpad — BM25 en vectoren — levert een eigen ranglijst op. RRF kent punten toe op basis van positie en telt deze op, zodat geen enkel zoekpad de resultaten domineert. - Hoeveel vectoren per document heb je nodig in een RAG-pipeline?
Een effectieve aanpak is één vector voor de pagina-inhoud en vijf vectoren voor automatisch gegenereerde vragen. De vraagvectoren vangen zoekopdrachten op die conceptueel overeenkomen maar andere woorden gebruiken. De vraagvectoren verdienen een hoger gewicht (1.25) dan de contentvector (0.75). - Waarom vindt een zoekmachine soms niet het juiste resultaat ondanks relevante content?
Traditionele zoekmachines werken op woordovereenkomst. Wanneer een gebruiker “verdoving in je rug” zoekt terwijl de pagina “Ruggenprik” heet, is er geen woordoverlap. Vectorzoeken lost dit op door op betekenis te zoeken in plaats van op woorden. - Hoe test je de kwaliteit van zoekresultaten in een RAG-pipeline?
Stel een testset samen van realistische zoekopdrachten op basis van echte zoekdata, voer deze geautomatiseerd uit tegen verschillende configuraties, en laat een LLM de resultaten beoordelen op top-1 relevantie, top-5 relevantie en keyword match. - Wat is het verschil tussen keyword search en semantic search in een RAG-systeem?
Keyword search (BM25) zoekt naar exacte woorden en werkt het best bij korte zoektermen. Semantic search vergelijkt betekenissen via vectoren en vindt ook resultaten zonder woordoverlap. In de praktijk presteren ze het best in combinatie: BM25 domineert bij keywords, vectoren bij uitgeschreven vragen. - Wanneer helpen vectoren wél en wanneer niet bij zoeken?
Vectoren helpen bij natuurlijke taal, typefouten en afwijkend woordgebruik. Ze werken averechts bij exacte keyword-zoekopdrachten waar BM25 direct de juiste pagina vindt. Het omslagpunt ligt bij de overgang van losse zoektermen naar uitgeschreven vragen (circa 3 woorden). - Moet je vectorgewichten dynamisch aanpassen per zoekopdracht?
In theorie wel: keywords presteren beter met lage vectorgewichten, vragen met hogere. In de praktijk levert dynamische aanpassing slechts ~2% verbetering op. Een vaste instelling van content=0.75 en vragen=1.25 werkt als robuust compromis. - Wat heeft meer impact op zoekresultaten: betere vectorgewichten of betere content?
Betere content. Vectorgewichten hebben slechts 3,5% invloed op het eindresultaat. Duidelijke paginatitels, relevante trefwoorden en synthetische vragen die aansluiten bij het taalgebruik van zoekers leveren meer op dan technische optimalisatie.